AutoTrain - Part 1: Ingredients
07 Oct 2021A Config First Approach
As we have discussed in the previous blog, our goal is to decouple moving parts from fixed parts so that a user can focus more time on tweaking parameters and hyperparameters of an experiment and less time setting up the code to train. The first step is going to create a framework that lets user condense, as much as possible, all important information for an experiment into a readable format.
To achieve this we have indentified and tweaked spacy-project’s awesome parser. Let’s dive straight into a sample configuration file
Below is sample file for storing information about downloading data for mnist -
[project]
version = 0.0.1
name = mnist
root = /home/me/projects/${project.name}
[project.data]
source = https://files.fast.ai/data/examples/mnist_tiny.tgz
root = ${root}/data/
And here’s the code to parse the data
from torch_snippets.registry import parse
from fastdownload import FastDownload
config = parse('config.ini')
print(config.project.version) # 0.0.1
print(config.project.data.root) # /home/me/projects/mnist/data
Context Awareness
- Unlike standard ini, we are able to resolve the variables using a parser. This lets us have several benefits -
- Multiple components in the experiment can be dynamically manipulated without worrying about bookkeeping.
- As you can see in above example, changing the project name will change where the data is downloaded on the disk.
- User is free to hardcode their own location or reuse variables present in the config file itself.
- All the variables can be called by using
object.header.section.sub_section.variablenotation.- This is applicable to any depth.
- You get tab completion for free.
Every project will have a different logic to download data. It is meaningful to wrap it up as part of config file too. But ini files can only hold primitive objects like ints, strings or lists. Creating a function registry is a natural way to overcome this limitation.
Builtin Registry
We have a builtin registry mechanism to point functions using string names. It works in 3 steps.
1. Create a section with function you want to refer to
- Here, the function is going to be called under the variable
project.data.download, - the function that we will be writing will be registered under the name
download_mnist, and - it will take the variables
baseandsourceas inputs
[project]
version = 0.0.1
name = mnist
root = /home/me/projects/${project.name}
[project.data]
source = https://files.fast.ai/data/examples/mnist_tiny.tgz
root = ${root}/data/
[project.data.download]
@download_function = download_mnist
base = ${project.data.root}
source_url = ${project.data.source}
2. Write the function and register it
- First we are creating a new registry called
download_function - The function is created with a decorator
- The function itself is wrapped to return the main function of interest, because we want our
project.data.downloadobject to be a callable function and not some static variable.
from torch_snippets.registry import registry
registry.create('download_function')
@registry.download_function.register("download_mnist")
def wrapper(base, source_url):
def fastdownloader():
import fastdownload
downloader = fastdownload.FastDownload(
base=base,
data='./',
module=fastdownload)
return downloader.get(source_url)
return fastdownloader
3. Parse and Resolve
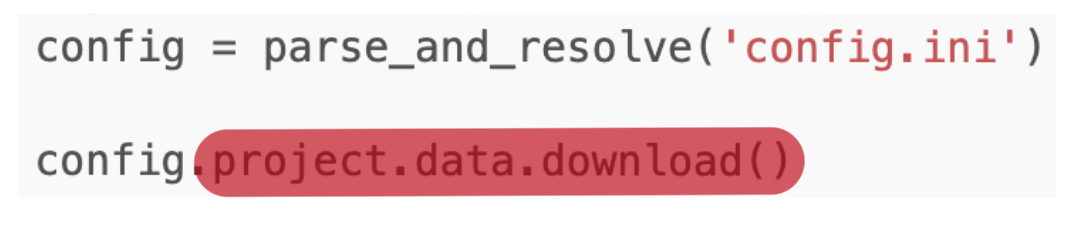
Parsing as we have done previously will only return the string form of the function, i.e., config.project.data.download == "@download_function". Resolving it, will search for a registered function under the name download_mnist and assign it to the variable so that it can be called like so -
from torch_snippets.registry import parse_and_resolve
import custom_functions
config = parse_and_resolve('config.ini')
config.project.data.download()
Here’s the summary in pictures -


Ingredients for Experiment
With such a functionality we are able to store information about everything related to an experiment in exactly one .ini file and one .py file.
We can store information under pertinent headings with human readable names for each variable. Drawing a cooking analogy, we are going to call this file as ingredients.
Here is how the ingredients for training MNIST would look like
[project]
version = 0.0.1
name = mnist-classification
root = /home/me/projects/${project.name}
[project.data]
source = https://files.fast.ai/data/examples/mnist_sample.tgz
root = ${root}/data/
[project.meta]
task = classification
n_classes = 10
[model]
version= 0.0.0
[model.architecture]
backbone = resnet18
output_classes = ${project.n_classes}
[training]
[training.load_dataset]
@load_dataset = load_mnist_from_disk
source = ${projeect.data_root}
[training.preprocess]
@preprocess = divide_by_255
[training.scheme]
epochs = 10
batch_size = 128
early_stop = True
[training.model]
save_dir = ${project.root}/models/
save_name = ${save_dir}/${model.version}/model.pth
save_all_checkpoints = False
[testing]
debug = False
[testing.preprocess]
@preprocess = resize_and_divide_by_255
Here’s the python file that contains the custom functions to support above ingredients.
from torch_snippets.registry import registry
registry.create('load_dataset')
registry.create('preprocess')
@registry.load_datset.register('load_mnist_from_disk')
def wrapper(source):
def loader():
return X, y
return loader
@registry.preprocess.register('divide_by_255')
def wrapper():
def preprocess(input):
return input/255.
return preprocess
@registry.preprocess.register('resize_and_divide_by_255')
def wrapper():
from torch_snippets import resize
def preprocess(input):
input = resize(input, (28,28))
return input/255.
return preprocess
Bottom line
Every experiment has ingredients. AutoTrain stores and tracks them in .ini (and supported by .py) files.
Next we will see how the fixed components, a.k.a. recipes, are coded in AutoTrain to take advantage of such ingredients.