AutoTrain - Part 2: Recipes
09 Oct 2021We have seen how to setup the ingredients for an experiment. The next step is to create the necessary files to use these ingredients in a way that training and validation can be done in one line.
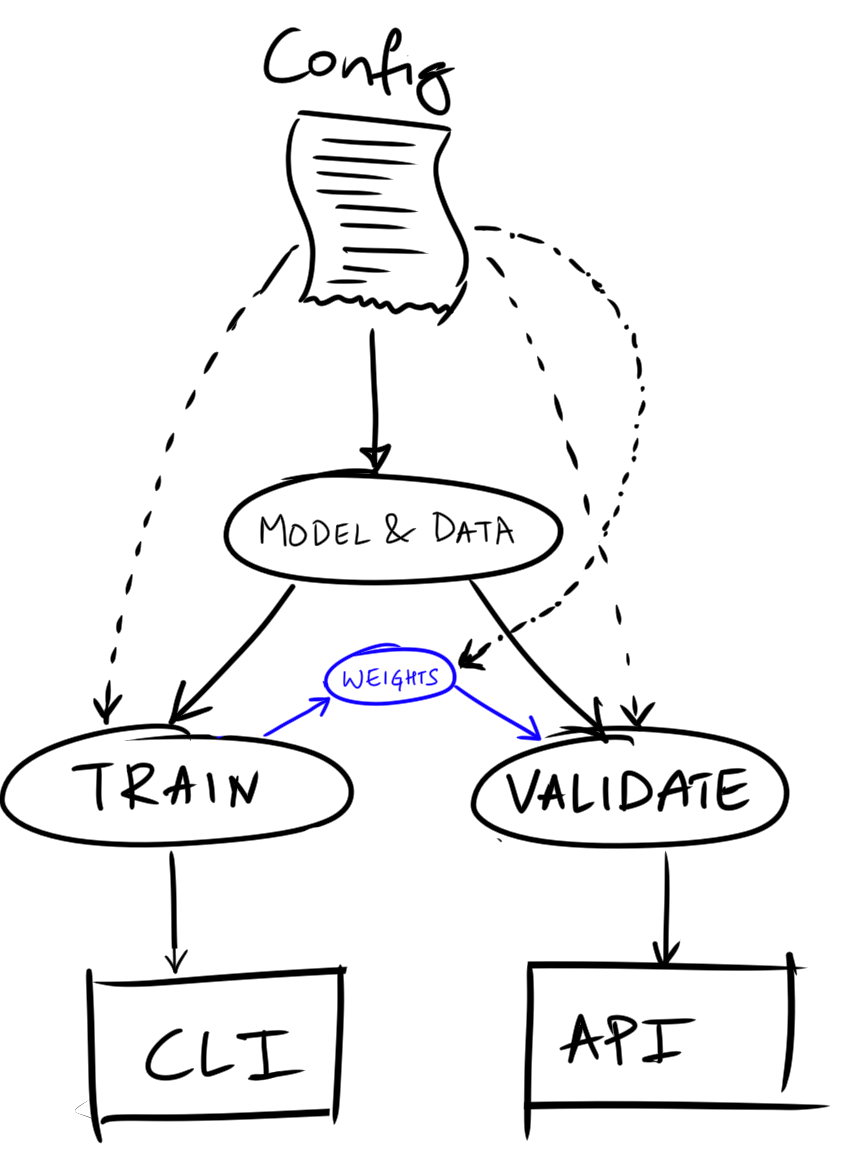
All the recipes can be summarized into the following files
config.ini --> Ingredients
custom_functions.py --> User inputs that suppliment config.ini
model.py --> Base model (and optional dataloaders + learner during training)
train.py --> Training logic
validate.py --> Validation logic
main.py --> Command line and API logic
Let’s create the recepie for MNIST ingredients that we have created in the previous article.
The first two files were already discussed in previous post.
The common base for training and validation is the model itself. It can be then loaded into train / validate files and do the needed tasks. Let’s start there.
model.py
from auto_train.common import Task
from auto_train.classification.custom_functions import *
from auto_train.classification.timmy import create_timm_model
class ClassificationModel(Task):
def __init__(self, config, inference_only=True):
super().__init__(config)
config = self.config
self.model = create_timm_model(
config.architecture.backbone.model,
n_out=config.project.meta.num_classes)
if inference_only:
self.dls = self.get_dataloaders()
self.learn = Learner(
self.dls, self.model,
splitter=default_split,
metrics=[accuracy])
def get_dataloaders(self):
training_dir = str(P(self.config.training.dir).expanduser())
if not os.path.exists(training_dir):
print(f'downloading data to {training_dir}...')
self.download_data()
dls = self.config.training.data.load_datablocks(self.config)
return dls
> Base Task can be found in source code at Base Task can be found in source code at AutoTrain/auto_train/common/base.py
This is used for repetitive tasks like parsing config and downloading dataset if it doesn't exist
> Creates a model using timm library
> Optionally loads the dataloaders if model is going to be trained
self.model is responsible for loading the right architecture. timm is an excellent library that can create a pretrained model just by using a string as input. We load the data using fastai’s datablocks api.
train.py
Once the model and learner are created, loading it for training is easy
import ...
def train_model(config: P):
task = ClassificationModel(config)
learn = task.learn
model = task.model
config = task.config
training_scheme = config.training.scheme
try:
load_torch_model_weights_to(model, config.training.scheme.resume_training_from)
except:
logger.info('Training from scratch!')
try:
lr = config.training.scheme.learning_rate
except:
lr = find_best_learning_rate(task)
logger.info(f"Using learning rate: {lr}")
learn.fine_tune(
training_scheme.epochs, lr,
freeze_epochs=training_scheme.freeze_epochs
)
makedir(parent(training_scheme.output_path))
save_torch_model_weights_from(model, training_scheme.output_path)
> Load the task and its components
> Resume training if weights are found
> Find best learning rate if lr is not given in config
> Train the model with pretrained weights
> Save the model to designated directory
validate.py
Once a model is trained the same architecture can be loaded along with the trained weights using the config file.
import ...
task = ClassificationModel(config='configs/mnist.ini', inference_only=True)
learn, config, model = task.learn, task.config, task.model
weights_path = config.training.scheme.output_path
load_torch_model_weights_to(model, weights_path)
def infer(img_path):
logger.info(f'received {img_path} for classification')
pred, _, cnf = learn.predict(img_path)
prediction = {
'prediction': pred,
'confidence': f'{max(cnf)*100:.2f}%'
}
if 'postprocess' in dir(config.testing):
return config.testing.postprocess(prediction)
else:
return prediction
> Load the same task as loaded in training, this time inference will be True so no dataloaders will be loaded
> Since the weights were already saved during training, load them up here
> Post process if it exists else return raw prediction
main.py
Finally all of it can be composed into a single file that will expose command line and api
from fastapi import APIRouter, File, UploadFile, BackgroundTasks
import typer
from io import BytesIO
from PIL import Image
import os
from loguru import logger
router = FastAPI()
cli = Typer()
@cli.command()
def train(config=None):
from auto_train.classification.train import train_model
train_model(config)
@router.post('/validate/')
async def validate(img: UploadFile = File(...)):
from auto_train.classification.infer import infer
image = Image.open(BytesIO(img.file.read()))
logger.info(img.filename)
img_path = f'test_images/from_api/{img.filename}'
image.save(img_path)
return infer(img_path)
if __name__ == '__main__':
cli()
> Use `typer`'s utility to create a command line functionality
$ python main.py train --config='configs/mnist.ini'
> FastAPI will expose an endpoint localhost:8889/validate/
which will take an image and return the predictions
Conclusion
As you can see, we are using config.header.objects in a number of places where one is expected to give inputs and store outputs. The rest of the code is largely the same, i.e., we can use the same set of files to train any number of classification tasks without worrying about creating duplicate code bases for each project. Let’s go through ingredients of Classification, Object Detection and Segmentation experiments to understand how easy it is to train with a good fixed base.